
BraveTiger
CH5. 머신러닝_Ensemble(1) - Voting/Bagging 본문
앙상블 학습(Ensemble)
여러 개의 분류기를 생성하고 그 예측을 결합함으로써 보다 정확한 최종 예측을 도출하는 기법
분류기(= base model, weak model, classifier, base learner, single learner 등 다양한 용어로 불린다.)
앙상블 학습의 목표는 다양한 분류기의 예측 결과를 결합함으로 단일 분류기보다 신뢰성이 높은 예측값을 얻는 것
- 앙상블의 유형은 일반적으로 보팅(voting), 배깅(bagging), 부스팅(boosting)으로 구분할 수 있으며 이외 스태킹(stacking) 등의 기법이 있다.
- 대표적인 배깅은 랜덤 포레스트
- 대표적인 부스팅은 에이다 부스팅, 그래디언트 부스팅, XGB, LGBM
- 일반적으로 정형 데이터의 분류나 회귀에서 GBM 부스팅 계열의 앙상블이 전반적으로 높은 예측 성능을 나타낸다.
앙상블의 특징
- 단일 모델의 약점을 다수의 모델로 결합하여 보완
- 뛰어난 성능을 가진 모델로 구성하는 것보다 성능이 다소 떨어지지만 서로 다른 유형의 모델을 섞는 것이 전체 성능에 도움이 될 수 있음
- 결정 트리의 단점인 과적합을 수십 ~ 수 천개의 분류기를 결합하여 보완
1. 보팅(Voting)
- 여러 모델에서 구해진 예측값들을 투표를 통해 결정하는 방식
- 서로 다른 알고리즘 여러 개를 결합하여 사용
- Hard voting과 Soft voting 방식이 있다.
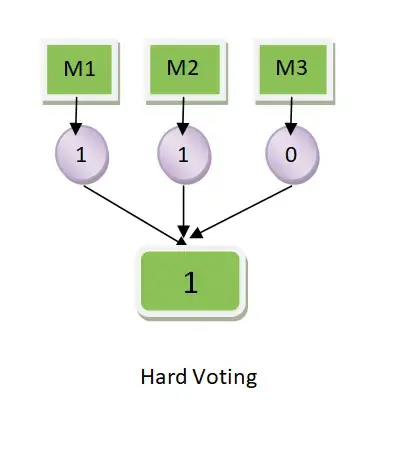
Hard voting: 다수의 분류기가 예측한 결과값을 최종 결과로 선정
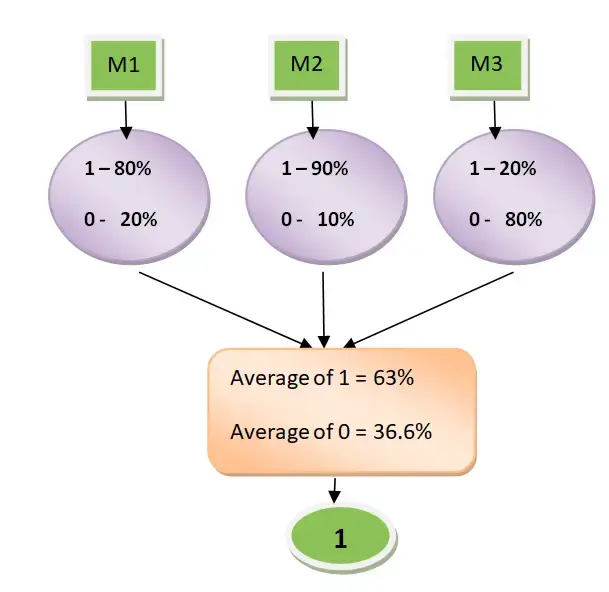
Soft voting: 각 알고리즘이 예측한 값의 확률의 평균하여 결정
2. 배깅 Bagging
- Bootstrap Aggregating의 약자
- 각각의 샘플을 여러 번 뽑아 각 모델을 학습시켜 결과를 집계하는 방법
- 여러 개의 결정 트리 분류기가 전체 데이터에서 배깅 방식으로 각자의 데이터를 샘플링해 개별적으로 학습 수행 후 최종적으로 모든 분류기가 보팅을 통해 예측 결정
- 랜덤 포레스트에서 분류기는 각각 개별적인 개별 트리이지만 개별 트리가 학습하는 데이터 셋은 전체 데이터에서 일부가 중첩되게 샘플링된 데이터 세트이다.
※Bootstrap Sampling
- 따라서 복원 추출을 통해 원래의 데이터 수만큼 크기를 같도록 하는 샘플링 방법 Bootstrap을 사용한다.
- 부트스트랩은 복원 추출을 허용한 표본 재추출 방법이다.
- 즉, 데이터 내에서 반복적으로 샘플을 사용하는 resampling 방법 중 하나로 하나의 모델에 대해 데이터를 추출할 경우 중복된 데이터가 있을 수 있다.
- 랜덤 포레스트의 n_estimators = k로 개수를 조정한다.
ex) 전체 데이터가 10,000개 있다고 가정했을 때
데이터 샘플링 -> 10,000개 => 서브세트#1
데이터 샘플링 -> 10,000개 => 서브세트#2
데이터 샘플링 -> 10,000개 => 서브세트#3
.....
데이터 샘플링 -> 10,000개 => 서브세트#n

앙상블(보팅, 배깅) 실습
https://colab.research.google.com/drive/1cD0kco15k9JZ9TczJDO8idkweCunZ_Qx#scrollTo=ouD-U4fQGU7k
Google Colaboratory Notebook
Run, share, and edit Python notebooks
colab.research.google.com
'취업 준비 > AIVLE SCHOOL' 카테고리의 다른 글
| 미니프로젝트 3차 회고 (0) | 2023.03.28 |
|---|---|
| CH5. 머신러닝_Ensemble(2) - Boosting (0) | 2023.03.28 |
| CH5. 머신러닝_Feature Selection/Feature importance (0) | 2023.03.27 |
| CH5. 머신러닝_회귀(3) (0) | 2023.03.27 |
| CH5. 머신러닝_DecisionTreeClassifier (0) | 2023.03.27 |


